Introducing Revka: A Memory-Native Multi-Agent Runtime
https://github.com/KumihoIO/Revka
Stateless agents are easy to demo and hard to trust.
Ask a model to summarize a document, call a tool, write a patch, or hand off a task, and the interaction can look intelligent in the moment. But the moment is the problem. Once the response is sent, most agent stacks lose the thread. They forget what they learned yesterday. They cannot reliably explain why one agent handed work to another. They treat provenance as a log file, memory as a plugin, and trust as a dashboard number someone may wire in later.
That breaks faster when you add more agents.
Multi-agent systems depend on continuity. A supervisor needs to know which worker has succeeded before. A handoff needs to preserve context without replaying the entire chat. A workflow needs to know that an upstream artifact was produced, revised, tagged, and approved. A team of agents needs a shared substrate, not a pile of disconnected transcripts.
Revka is built around that premise.
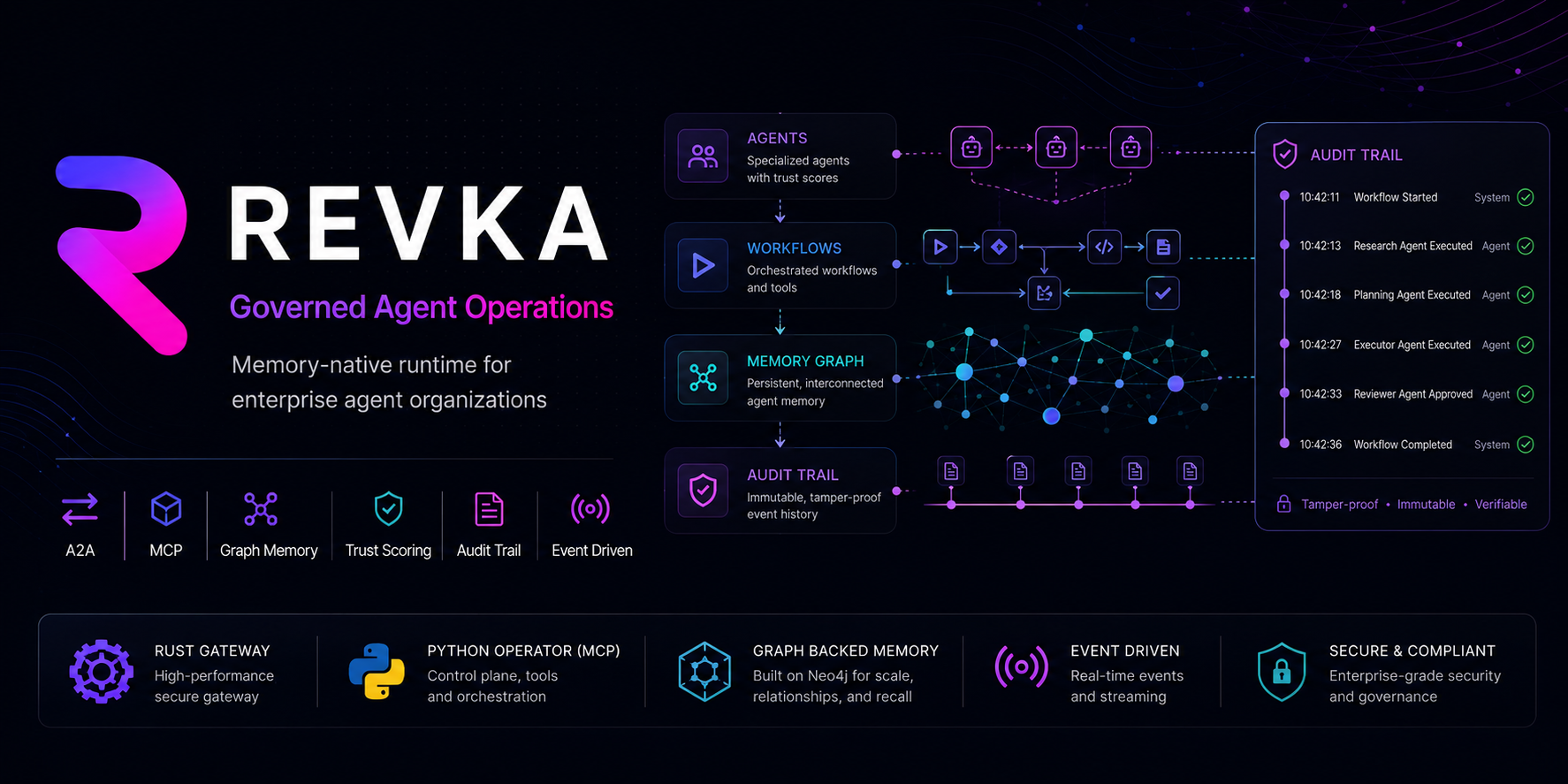
Revka is a Rust-native AI agent runtime with persistent cognitive memory, multi-agent orchestration, and a shared skill/template marketplace. Every agent session, plan, skill, and trust score lives in a graph. If it happened, it is queryable.
That is the shift: memory not as a feature, but as the substrate every agent wakes up in.
What Revka Is
Revka is an agent OS for running useful, inspectable, memory-aware agent systems on your own machine.
It combines three layers:
| Layer | What it does |
|---|---|
| Revka | Rust gateway, daemon, agent loop, tools, channels, embedded dashboard, CLI, desktop shell, and Operator integration |
| Kumiho SDKs | Graph and cognitive-memory SDKs used by agents and workflows |
| Kumiho server | Version-controlled, typed-edge graph backend for memory, provenance, workflows, trust, and audit trails |
Revka itself is open source under MIT or Apache 2.0. The Rust runtime builds from the ZeroClaw lineage, with attribution in the repo’s NOTICE, and moves the architecture toward Kumiho-backed persistent
cognition.
That lineage matters. ZeroClaw showed what a self-hosted Rust agent runtime can look like: one binary, channels, tools, hardware, a gateway, and a dashboard. OpenClaw has pushed the channel-first local assistant idea into chat, voice, mobile, and companion apps. Sim has made visual workflow authoring approachable with a strong canvas-first agent builder. Hermes has focused on a self-improving single-agent loop with sub-agent delegation.
Revka sits in a different place: it is not only a channel gateway, workflow canvas, or delegation tool. It is a memory-native runtime where sessions, plans, workflow runs, outcomes, skills, and trust records are first-class graph objects.
Without a reachable Kumiho endpoint, Revka can still run in a graceful stateless single-agent mode. That is useful for demos and CI. But the real system appears when the graph is online: cross-session memory, provenance, audit chains, reactive workflows, and team-level continuity.
The 30-Second Tour
Install with one command:
# macOS / Linux / WSL
curl -fsSL https://revka.ai/install.sh | bash
# Windows (PowerShell)
irm https://revka.ai/install.ps1 | iex
The installer sets up revka and the Kumiho and Operator Python MCP sidecars under ~/.revka/, runs revka onboard for provider and API-key setup, and opens the dashboard at:
http://127.0.0.1:42617
Then you can run:
revka gateway # start the gateway + dashboard
revka agent -m "Hello" # one-shot agent run
revka status # health check
revka doctor # diagnose config, sidecar, and channel issues
revka daemon # long-running autonomous runtime
Revka is BYOK. It supports 14+ providers, including Anthropic, OpenAI, OpenRouter, Ollama, GLM, Gemini, Bedrock, Azure OpenAI, Copilot, Claude Code, Codex CLI, and router wrappers. Operator orchestration uses provider credentials or OAuth, while spawned agents can invoke Claude Code or Codex CLI as subprocesses. That means your CLI subscription can become the spawned-agent runtime without turning every worker call into separate API spend.
Kumiho’s free tier starts at 5,000 nodes, with no credit card. A 30-day Studio trial activates when Revka stores its first memory: 500,000 nodes, full audit visibility, and you keep what you build when you return to free.
One Binary, One Entry Point
Revka’s front door is a Rust gateway built with Axum and Tower. It serves more than 90 REST endpoints, seven WebSocket routes, server-sent event streams, and an embedded React 19 / TypeScript / Tailwind 4
dashboard compiled directly into the binary with rust-embed.
That gives you one static binary and one local entry point.
The dashboard exposes 17 primary sidebar routes across orchestration, operations, and inspection. You can inspect workflows, memory, sessions, agents, trust records, and runtime state from the same place you use to drive the system.
This is important because agent systems fail when the runtime becomes invisible. Revka treats the dashboard as part of the runtime surface, not a separate monitoring afterthought.
Operator: The Workflow Orchestrator
Revka’s workflow engine lives in Operator, a Python MCP sidecar that runs declarative YAML workflows.
Operator currently supports 23 step types. The important part is not the number. It is what the primitives allow:
supervisor for LLM-driven delegation, map_reduce for fan-out and reduction, group_chat for multi-agent discussion, handoff for agent-to-agent transfer, human_approval and human_input for
checkpoints, plus steps for agents, shell commands, Python, conditionals, parallel execution, loops, notifications, tagging, outputs, images, email, and more.
That makes Operator the place where multi-agent behavior becomes explicit. A workflow is not just a script. It is a plan whose execution can be recorded, revised, tagged, and connected back to memory.
Here is a small workflow that shows the core idea:
name: data-pipeline-distribute
description: "Format and prepare an executive summary for distribution."
triggers:
- on_kind: "executive-summary" # Watch for this entity kind
on_tag: "ready" # When tagged with this
input_map:
source_entity: "${trigger.entity_kref}"
steps:
- id: format
type: agent
agent:
agent_type: claude
role: researcher
prompt: |
You have received an executive summary (entity: ${inputs.source_entity}).
Format this into a distribution-ready document with TL;DR and action items.
timeout: 180
- id: publish
type: output
depends_on: [format]
output:
format: markdown
template: "${format.output}"
entity_kind: "distribution-package"
entity_tag: "delivered"
In 25 lines, you get the whole memory-native story.
A workflow watches for an executive-summary entity tagged ready. When that appears in the graph, Operator launches the workflow. The agent formats the summary. The output step publishes a new
distribution-package entity tagged delivered.
That output is not just a file. It is a graph event.
A downstream workflow can now react to the distribution-package without cron, webhook glue, or polling. The memory layer is also the orchestration layer.
The Memory Graph Is The Event Bus
Most systems store memory after the fact. Revka uses Kumiho memory as active infrastructure.
When a workflow publishes or tags an entity, the daemon emits a revision event. Any workflow with a matching triggers: block can launch automatically. Revising or tagging a Kumiho item becomes a
side-effect-bearing action that fans out into downstream pipelines.
That is why the YAML example matters. It is not only showing a workflow DSL. It is showing memory as an event bus.
The same graph that remembers what happened also decides what can happen next.
Why Memory-Native Changes The System
A stateless LLM call forgets everything once the response is sent. Kumiho gives Revka agents four properties that stateless agents do not have.
First, cross-session continuity. What an agent learned yesterday can still matter today.
Second, graph-structured recall. Memories carry typed edges such as DERIVED_FROM, DEPENDS_ON, REFERENCED, CONTAINS, CREATED_FROM, and BELONGS_TO. That means provenance queries can traverse
decision chains instead of fuzzy-matching old text.
Third, provenance. A memory can link back to the sources, workflows, sessions, and artifacts that produced it.
Fourth, a shared substrate. Multiple agents on the same Kumiho control plane can see each other’s reflections. That is the foundation for handoff, supervisor delegation, team memory, and long-running collaboration.
Revka’s own namespaces make the point:
Revka/AgentPool/ — Agent templates
Revka/Plans/ — Execution plans with deps + status
Revka/Sessions/ — Session summaries, handoff notes
Revka/Goals/ — Strategic/tactical/task goals
Revka/AgentTrust/ — Trust scores + interaction history
Revka/Teams/ — Team bundles
Revka/WorkflowRuns/ — Operator workflow run records
Revka/Outcomes/ — Per-agent outcomes for trust scoring
CognitiveMemory/Skills/ — Shared cross-agent skill library
This is what separates Revka from frameworks that add “memory” as a vector-store attachment. In Revka, the system’s own operating state lives in memory.
If it happened, there is a trace.
Trust, But Don’t Oversell It
Revka also records trust outcomes for agent runs. Today, outcomes are scored with simple weights: success is 1.0, partial is 0.5, and failed is 0.0. The trust score is the average over total runs,
persisted under Revka/AgentTrust/<template_name> with recent outcomes retained for inspection.
That is useful now because trust is recorded, queryable, and visible in the dashboard’s AgentTrust view.
The next step is more interesting: wiring those trust scores into supervisor agent selection so higher-trust agents are preferred for delegation. That is not something to overclaim today. It is the right follow-up post once the wiring is real.
Where Revka Stands Out
The current agent ecosystem is converging on a few obvious shapes.
Some projects start with channels: one assistant connected to every surface you use. Some start with visual workflow authoring: a canvas where agents, tools, branches, and integrations become nodes. Some start with a single powerful agent that learns, delegates, and improves its own skills over time. Some start with a self-hosted runtime and build outward into tools, hardware, and dashboards.
Revka’s bet is that all of those become more useful when memory is structural.
A channel gateway is better when conversations become durable session memory. A workflow engine is better when every run produces queryable graph artifacts. A supervisor is better when handoffs, outcomes, and trust have history. A skill marketplace is better when skills are not just files, but shared objects agents can reference, revise, and reuse.
That is the agent OS argument: not “one more agent framework,” but a runtime where agents, workflows, memory, and inspection share the same operating substrate.
What Comes Next
This post is the introduction. The deeper pieces deserve their own space.
Trust scoring needs a dedicated post once supervisor selection is wired to trust rankings.
Reactive graph workflows deserve a full walkthrough: how tags, revisions, triggers, and workflow launches compose into event-driven agent pipelines.
The YAML DSL deserves a reference-style tour of the 23 step types, especially supervisor, map_reduce, group_chat, handoff, and human approval.
And Revka needs its own benchmark or case study: a concrete workload that shows what memory-native orchestration changes in practice, the same way earlier Kumiho posts used LoCoMo-Plus to make the memory layer tangible.
For now, the fastest way to understand Revka is to run it.
# macOS / Linux / WSL
curl -fsSL https://revka.ai/install.sh | bash
revka gateway
# Windows (PowerShell)
irm https://revka.ai/install.ps1 | iex
revka gateway
Open:
http://127.0.0.1:42617
Then try a workflow, inspect the graph, and watch what changes when an agent runtime remembers what it did.